T-SQL (Transact-SQL) window functions are a category of functions in Microsoft SQL Server that perform calculations across a specified range of rows related to the current row within a result set. These functions operate on a set of rows that are defined by an OVER clause in the query, allowing for more advanced and flexible analytical processing compared to traditional aggregate functions.
Window functions are powerful for analytical and reporting tasks where you need to perform calculations over a specific range of rows rather than the entire result set. The OVER clause defines the window, specifying the partition, ordering, and framing of the rows involved in the calculation. These functions are widely used in scenarios such as ranking, pagination, and trend analysis in SQL queries.
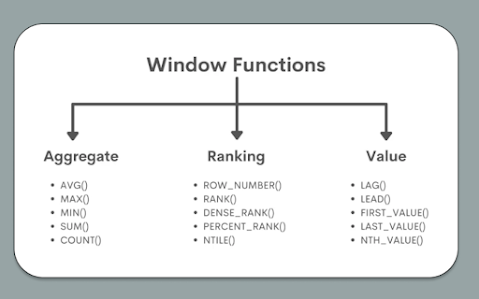
Here is a list of commonly used T-SQL window functions:
ROW_NUMBER(): Assigns a unique sequential integer to each row within a partition of the result set.
RANK(): Assigns a rank to each distinct row within a partition of the result set, with ties receiving the same rank and leaving gaps in the ranking sequence.
DENSE_RANK(): Similar to RANK(), but without gaps in the ranking sequence. Ties receive the same rank, and the next rank is not skipped.
NTILE(n): Divides the result set into "n" number of roughly equal parts, assigning each row a bucket number.
LEAD() and LAG(): Access data from subsequent or preceding rows within the result set, respectively. These functions are useful for comparing values across different rows.
SUM(), AVG(), MIN(), MAX() OVER(): These functions allow you to calculate cumulative or running aggregates over a specified window of rows.
FIRST_VALUE() and LAST_VALUE(): Retrieve the first or last value within a window of rows, respectively.
PERCENTILE_CONT() and PERCENTILE_DISC(): Calculate the percentile value within a specified range of rows.
The OVER clause and sorting
PARTITION BY and ORDER BY are two choices in the OVER clause that might induce sorting. All window functions allow PARTITION BY. However, it's not required. For the majority of the functions, ORDER BY is necessary.The data will be sorted based on the OVER clause, which might be the query's speed bottleneck, depending on what you attempt to do.
The OVER clause's Sequence BY option is necessary so that the database engine can "align up" the rows so that the function may be applied in the right order. Let's imagine you wish to use the ROW NUMBER function in the order of SalesOrderID.
The OVER clause's Sequence BY option is necessary so that the database engine can "align up" the rows so that the function may be applied in the right order. Let's imagine you wish to use the ROW NUMBER function in the order of SalesOrderID.
If you want the function to be applied in decreasing the order of TotalDue, the results will be different.
Let's see what the T-SQL query would look like in this scenario :
USE AdventureWorks<version>; GO SELECT SalesOrderID, TotalDue, ROW_NUMBER() OVER(ORDER BY SalesOrderID) AS RowNum FROM Sales.SalesOrderHeader; SELECT SalesOrderID, TotalDue, ROW_NUMBER() OVER(ORDER BY TotalDue DESC) AS RowNum FROM Sales.SalesOrderHeader; The results from the above queries would look like the below :  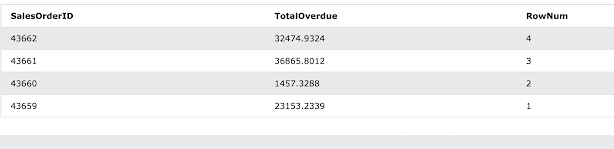 No sorting is required because the first query uses the cluster key as the ORDER BY option.  The second query includes a time-consuming sort procedure.  The ORDER BY phrase in the OVER clause is unrelated to the ORDER BY clause in the overall query, which may be quite different. The
only method to avoid sorting's speed hit is constructing a dedicated
index for the OVER clause. Itzik's book Microsoft SQL Server 2012
High-Performance T-SQL Using Window Functions explains how to use window
functions in high-performance T-SQL. The POC index is recommended by
Ben-Gan. (P)PARTITION BY, (O)ORDER BY, and (c)covering are the acronyms
for (P)PARTITION BY, (O)ORDER BY, and (c)covering. He
suggests placing any filtering columns in the key before the PARTITION BY and ORDER BY columns. Then, as included columns, add any extra
columns required to construct a covering index. You'll need to test how such an index affects your query and total workload, just like
everything else. Of
course, you won't be able to add an index to every query you create,
but if the efficiency of a query that employs a window function is
critical, you may follow this suggestion. Here's a list of indexes that will help you enhance your previous query: CREATE NONCLUSTERED INDEX test ON Sales.SalesOrderHeader (CustomerID, SalesOrderID) INCLUDE (TotalDue); When you restart the query, you'll see that the sort operation is no longer included in the execution plan:  FRAMINGFraming
is, in my opinion, the hardest topic to grasp while studying T-SQL
window methods. See the introduction to T-SQL window functions for
further information on the syntax. The following items require framing: ORDER BY window aggregates, such as FIRST VALUE LAST VALUE, are used for running totals or moving averages. Fortunately, framing isn't necessary most of the time, but it's all too simple to
skip the frame and go with the default. RANGE BETWEEN UNBOUNDED
PRECEDING AND CURRENT ROW is always the default frame. Speed will suffer while you will obtain the right results as long as the ORDER BY option contains a unique column or collection of columns. Here's an example of a comparison between the default and proper frames: SET STATISTICS IO ON; GO SELECT CustomerID, SalesOrderID, TotalDue, SUM(TotalDue) OVER(PARTITION BY CustomerID ORDER BY SalesOrderID) AS RunningTotal FROM Sales.SalesOrderHeader; SELECT CustomerID, SalesOrderID, TotalDue, SUM(TotalDue) OVER(PARTITION BY CustomerID ORDER BY SalesOrderID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS RunningTotal FROM Sales.SalesOrderHeader; Do let me know the output of the above query. You guys can compare that in the comment section and let me know. The
outcomes are the same, but the execution is vastly different.
Unfortunately, the implementation plan does not give you the truth in this scenario. Each query consumed 50% of the resources, according to
the report. The I/O operations on the first query will be in thousands, while in the second query, they would be 0! Yes, you heard that right! ConclusionT-SQL
window functions have been touted as high-performance options. They
make creating inquiries easier in my perspective, but you must
understand them well to achieve high performance. Although indexing can
help, you can't generate an index for every query you write. Framing is a
difficult concept to grasp, but it is critical if you need to scale up
to enormous tables. Other SQL and Database Articles you may like:
Thanks for reading this article so far. IF you like it then please share and if you have any questions, |
No comments:
Post a Comment